
Scansione e divisione dei PDF in base al testo specifico in essi contenuto
Oggi automatizziamo molti processi documentali. Volete riconoscere un testo specifico da un PDF? Volete utilizzare quel testo per dividere il file nelle pagine contenenti il testo specifico? Volete rinominare i file divisi utilizzando il testo usato per la divisione? Abbiamo la soluzione perfetta per voi.
L’azione PDF4me Workflows Split By Text risponde a tutte queste logiche documentali. I flussi di lavoro si concentrano in modo esclusivo sulla fornitura della migliore soluzione di automazione per i processi documentali. L’azione può anche memorizzare il testo negli appunti per rinominare i file con il testo, se necessario, durante il salvataggio. Vediamo ora, con un esempio di flusso di lavoro, come impostare questa azione.
Come scansionare e dividere i PDF in base a un testo specifico?
Nell’esempio che segue, creeremo un flusso di lavoro per dividere un file PDF utilizzando il testo specifico in esso contenuto e utilizzeremo il testo per rinominare i file divisi.
Iniziare lanciando la PDF4me Dashboard.
- Selezionare il pulsante Crea flusso di lavoro.
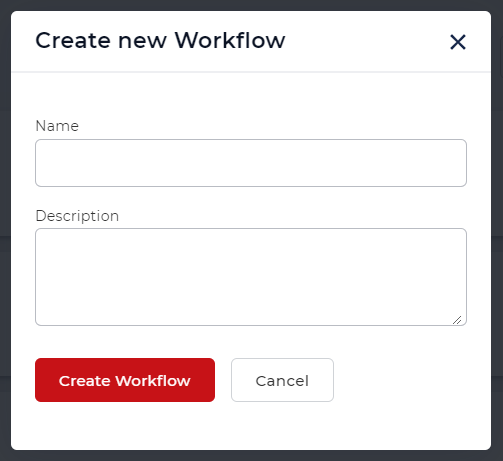
Aggiungere un trigger per avviare il flusso di lavoro
Aggiungete un trigger per dare il via all’automazione.
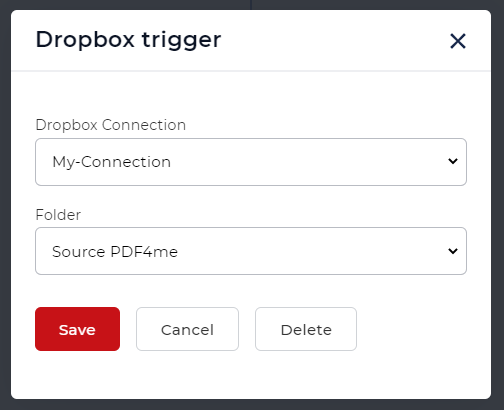
- Attualmente, i flussi di lavoro forniscono 2 trigger: Dropbox e Google Drive. Ad esempio, creiamo un trigger Dropbox.
Configurare la connessione e scegliere la cartella in cui sono attesi i file di input.
Per testare il flusso esatto, è possibile utilizzare questo PDF di esempio - Scaricare il file di esempio
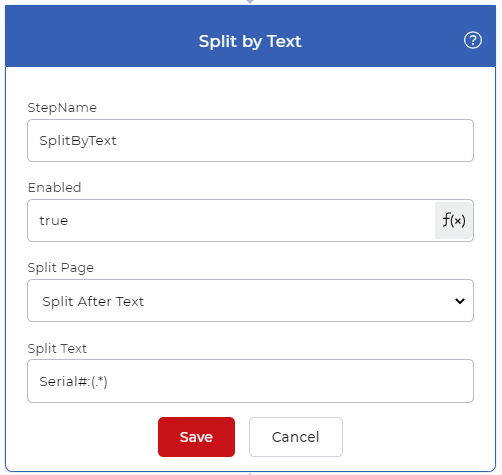
Aggiungere l’azione Dividi per testo
Aggiungere e configurare un’azione Dividi per testo per separare le pagine del file utilizzando il testo richiesto. Qui utilizziamo un’espressione regolare per rilevare il testo unico.
Seriale#:(.*)
La regex troverà i valori di testo che iniziano con ‘Serial#:’ e li dividerà in base alla condizione.
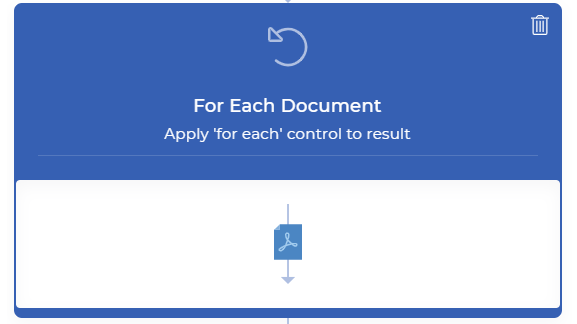
Aggiungere un controllo For Each Documet
Poiché Split By Text genera più documenti, è necessario un controllo For Each Document per gestire i file di output uno per uno. Il resto delle azioni deve essere incluso in questo controllo.
Aggiungere un Salva all’azione
I file di output devono essere salvati su cloud storage. Nel nostro caso d’uso, configuriamo un’azione Save to Dropbox. Nell’immagine qui sopra, si può vedere un’espressione per ottenere un testo dall’azione ‘Dividi per testo’. Per rinominare i file, è possibile utilizzare l’espressione regolare riportata di seguito nel parametro Output File Name.
``${file.pages[0].PageText}.pdf```
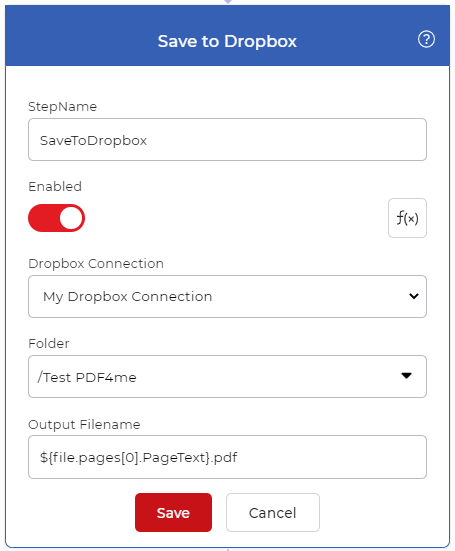
L’espressione passerà il testo dell’azione Dividi per PDF al parametro Nome file di output, in modo che i file vengano rinominati in base al testo letto.
Per ottenere l’accesso a Workflows è necessario un PDF4me Subscription. È anche possibile ottenere un Daypass e provare Workflows per vedere come può aiutare ad automatizzare i lavori sui documenti.


